
学习的目的是应用,不是为了学习而学习。
从书本上学知识,有三个过程。
- 第一个过程,我能理解了
- 第二个过程,我能消化了
- 第三个过程,我能应用了
如果只停留在第一个过程,那么学到的知识很快也就会忘记,并不能给自己带来能力上的提升,反而会让自己越来越失望,觉得学的东西怎么都忘记了呢?
python提供了两大类属性管理的方法,分别是:1. 基于运算符重载 2. 基于descriptor协议
|
|
防止循环调用的方法: 1. 使用属性字典 2. 调用父类的方法 3. 调用其他对象的方法
__getattr__和__getattribute__一般用在实现委托器模式的代码中。
|
|
基于descriptor的属性管理方法必须在新式类中使用。
|
|
property是descriptor协议的一种特例,基于property的属性管理方法必须在新式类中使用。
|
|
使用装饰器的property
|
|
正常的函数调用,会按照之前的规则拦截,但是对于重载函数的调用,拦截规则如下:
2.6
| 类别 | 隐式调用 | 显式调用 |
|---|---|---|
| __getattr__ | 若没定义则拦截 | 若没定义则拦截 |
| __getattribute__ | 不拦截 | 拦截 |
3.0
| 类别 | 隐式调用 | 显式调用 |
|---|---|---|
| __getattr__ | 不拦截 | 若没定义则拦截 |
| __getattribute__ | 不拦截 | 拦截 |
既然property是descriptor的一种特例,那么它们之间是什么关系?
|
|
__slots__也是基于descriptor协议实现的。
A chunk is simply a sequence of commands(or statements)
lua里面的语句分隔符没有实际意义,只是让人看上去比较清楚。
|
|
lua里面的变量名可以除数字开头的字母、数字、下划线的任意组合,但是以下划线开头后跟大写字母的变量是lua语言保留的。lua是大小写敏感的。以下关键字也是lua语言保留的。
|
|
注释
|
|
全局变量
lua里面的全局变量不需要显式声明。如果没有声明就使用,将得到nil。
当将一个变量赋值为nil时,意思是告诉lua编译器回收这个变量占用的内存。
解释器
|
|
解释器在执行之前会寻找LUA_INIT_5_2或LUA_INIT全局变量,若内容是@filename,则执行该文件,否则执行全局变量的内容。
|
|
|
|
|
|
|
|
|
|
redis.conf
|
|
sentinel.conf
|
|
redis总共200个命令,其中字符串对象相关命令24个、列表对象相关命令17个、哈希对象相关命令15个、集合对象相关命令15个、有序集合对象相关命令21个。
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| SET key value [EX seconds] [PX milliseconds] [NX | XX] | O(1) | 覆写之前的值,若有过期时间,则删除 | |
| SETEX key seconds value | O(1) | 原子操作 | |
| SETNX key value | O(1) | ||
| GET key | O(1) | ||
| APPEND key value | O(1) | ||
| STRLEN key | 返回key指定的字符串的长度 | ||
| SETRANGE key offset value | 覆写字符串的一部分 | O(1) | |
| GETRANGE key start end | 获取字符串的一部分 | O(N) | |
| INC key | O(1) | ||
| INCBY key increment | O(1) | ||
| INCBYFLOAT key increment | O(1) | ||
| DECR key | O(1) | ||
| DECRBY key decrement | O(1) |
Design pattern: Locking with SETNX
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| BLPOP key [key …] timeout | LPOP的阻塞版本 | O(1) | |
| BRPOP key [key …] timeout | RPOP的阻塞版本 | O(1) | |
| BRPOPLPUSH source destination | RPOPLPUSH的阻塞版本 | O(1) | |
| LINDEX key index | 返回指定索引处的值 | O(N) | 表头从0开始 表尾从-1开始 |
| LINSERT key BEFORE | AFTER pivot value | 在列表某一项之前或之后添加元素 | O(N) | |
| LLEN key | 获取一个key指定的列表的长度 | O(1) | |
| LPOP | 移除并返回列表的第一个元素 | O(1) | |
| LPUSH key value [value …] | 插入一个或多个值到表头 | O(1) | 若key指定的列表不存在,则创建一个空的列表 |
| LPUSHX key value | 插入一个值到表头 | O(1) | 若key指定的列表不存在,则什么也不做 |
| LRANGE key start stop | 获取key指定的列表里的指定范围的元素 | ||
| LREM key count value | 删除列表中的元素 | O(N) | count>0 从表开始 count<0从表尾开始 count=0 删除所有 |
| LSET key index value | 设置索引处的值 | ||
| LTRIM key start stop | 截断列表 | O(N) | |
| RPOP | 移除并返回列表的最后一个元素 | O(1) | |
| RPOPLPUSH source destination | 移除并返回source指定的列表的最后一个节点并且将该节点放入destination指定的列表的表头 | O(1) | 原子操作 |
| RPUSH key value [value …] | 插入一个或多个值到表尾 | O(1) | 若key指定的列表不存在,则创建一个空的列表 |
| RPUSHX key value | 追加一个值到列表 | O(1) | 若key指定的列表不存在,则什么也不做 |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| HDEL key field [field …] | 删除指定的field | O(N) | |
| HEXISTS key field | 检查field是否存在 | O(1) | |
| HGET key field | 获取值 | O(1) | |
| HGETALL key | 获取key指定的哈希表中所有的field和value | O(N) | |
| HINCBY key field increment | 递增值 | O(1) | 若没有则创建 |
| HINCBYFLOAT key field increment | 递增值 | O(1) | 若没有则创建 |
| HKEYS key | 返回哈希对象中的所有键 | O(N) | |
| HLEN key | 获取key指定的哈希表中field的数量 | O(1) | |
| HMGET key field [field …] | 返回多个指定的field的值 | O(N) | |
| HMSET key field value [field value …] | 设置多个指定的键值对 | O(N) | |
| HSCAN key cursor [MATCH pattern] [COUNT count] | |||
| HSET key field value | 存储键值对 | O(1) | |
| HSETNX key field value | 设置键值对 | O(1) | 若存在则什么也不做 |
| HSTRLEN key field | 返回field指定的值的长度 | O(1) | |
| HVALS key | 获取哈希对象中的所有值 | O(N) |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| SADD key member [member …] | 增加多个成员到集合中 | O(1) | |
| SCARD key | 返回集合中的元素数量 | O(1) | |
| SDIFF key [key …] | 返回第一个key指定的集合里有的而其他key指定的集合里没有的所有元素 | O(N) | 差集 |
| SDIFFSTORE destination key [key …] | 将第一个key指定的集合里有的而其他key指定的集合里没有的所有元素存入destination指定的集合 | O(N) | |
| SINTER key [key …] | 返回所有key指定的集合的交集 | O(N*M) | 交集 |
| SINTERSTORE destination key [key …] | 将所有key指定的集合的交集存到destination集合 | O(N*M) | |
| SISMEMBER key member | 检查member是否是在key指定的集合里 | O(1) | |
| SMEMBERS key | 返回所有成员 | O(N) | |
| SMOVE source destination member | 从source指定的集合移动member到destination指定的集合 | O(1) | |
| SPOP key [count] | 移除并返回一个或多个随机元素 | O(1) | |
| SRANDMEMBER key [count] | O(1) | 当count>0时返回count个不同的元素,当count<0时,可以返回多个相同的元素 | |
| SREM key member [member …] | O(N) | ||
| SSCAN key cursor [MATCH pattern] [COUNT count] | |||
| SUNION key [key …] | 返回所有key指定的所有不同的元素 | O(N) | 并集 |
| SUNIONSTORE destination key [key …] | 将所有key指定的所有不同的元素添加到destination | O(N) |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| ZADD key [NX | XX] [CH] [INCR] score member [score member …] | 向key指定的有序集合中添加带有分值的字段 | O(lg(N)) | |
| ZCARD key | 获取key指定的有序集合里的元素数量 | O(1) | |
| ZCOUNT key min max | 返回分值在min和max之间的元素的数量 | O(lgN) | |
| ZINCBY key increment member | 增加指定成员的分值 | O(lnN) | |
| ZINTERSCORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM | MIN | MAX] |
交集 | O(N*K)+O(M*lgM) N是最小的有序集合的数量 K是有序集合的个数 M是结果有序集合的数量 | |
| ZLEXCOUNT key min max | 返回值在min到max之间的元素的数量 | O(lgN) | |
| ZRANGE key start stop [WITHSCORES] | 获取key指定的有序集合里的指定范围的元素 | O(lg(N)+M) | |
| ZRANGEBYLEX key min max [LIMIT offset count] | 返回值在min和max之间的元素 | O(lg(N)+M) | 元素的分值必须相等 |
| ZRANGEBYSTORE key min max [WITHSCORES] [LIMIT offset count] | 返回分值在min和max之间的元素 | O(lg(N)+M) | |
| ZRANK key member | 返回元素的排名 | O(lgN) | |
| ZREM key member [member …] | 删除指定的元素 | O(M*lgN) N是有序集合元素的数量 M是要删除的元素的数量 | |
| ZREMRANGEBYLEX key min max | 按照值删除指定范围的元素 | O(lg(N)+M) | |
| ZREMRANGEBYRANK key start stop | 按照排名删除指定范围的元素 | O(lg(N)+M) N是有序集合元素的数量 M是要删除的元素的数量 | |
| ZREMRANGEBYSCORE key min max | 按照分值删除指定范围的元素 | O(lg(N)+M) | |
| ZREVRANGE key start stop [WITHSCORES] | 以相反的顺序返回指定范围的元素 | O(lg(N)+M) N是有序集合元素的数量 M是要返回的元素的数量 | |
| ZREVRANGEBYLEX key max min [LIMIT offset count] | 按照值以相反的顺序返回指定范围的元素 | O(lg(N)+M) N有序集合元素的数量 M是返回的元素的数量 | 所有元素分值必须相等 |
| ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] | 按照分值以相反的顺序返回指定范围的元素 | O(lg(N)+M) | |
| ZREVRANK key member | 以相反的顺序返回元素的排名 | O(lgN) | |
| ZSCAN key cursor [MATCH pattern] [COUNT count] | |||
| ZSCORE key member | 返回元素的分值 | O(1) | |
| ZUNIONSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM | MIN | MAX] |
并集 | O(N)+O(MlgM) N是所有有序集合的元素之和 M是结果有序集合的元素总数 |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| EXPIRE key seconds | 设置key的超时时间 | O(1) | 对key指定的值得修改操作不会影响到超时时间 |
| PEXPIRE key milliseconds | 设置key的超时时间 | O(1) | 毫秒单位 |
| EXPIREAT key timestamp | 设置key的超时时间 | O(1) | 设置秒级时间戳 |
| PEXPIREAT key milliseconds-timestamp | 设置key的超时时间 | O(1) | 设置毫秒级时间戳 |
| PERSISIT key | 删除key上的超时时间 | O(1) | |
| TTL key | 返回有超时时间的关键字的剩余时间 | O(1) | 单位为秒 |
| PTTL key | 返回有超时时间的关键字的剩余时间 | O(1) | 单位为毫秒 |
| TIME | 返回服务器当前时间 | O(1) | 秒级时间戳+毫秒数 |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| SELECT index | 选择某个数据库 | 默认从0开始 | |
| DEL key [key …] | 删除指定的键 | O(N) | |
| RANDOMKEY | 从当前数据库中随机选择一个key | O(1) | |
| EXISTS key [key …] | 判断是否存在关键字 | O(1) | |
| DBSIZE | 返回当前数据库关键字的数量 | ||
| FLUSHALL [ASYNC] | 清空所有数据库 | O(N) | |
| FLUSHDB [ASYNC] | 清空当前数据库 | O(N) |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| SAVE | 以RDB文件的形式同步持久化数据库 | 该命令会阻塞所有其他客户端的操作 | |
| BGSAVE | 以RDB文件的形式异步持久化数据库 | ||
| LASTSAVE | 返回上次数据库执行保存的时间戳 | 客户端可以通过该命令来判断BGSAVE是否执行成功 | |
| BGREWRITEAOF | 启动一个AOF重写进程 |
| 命令 | 解释 | 时间复杂度 | 特别说明 | |
|---|---|---|---|---|
| CLIENT KILL [ip:port] [ID client-id] [TYPE noral | master | slave | pubsub] [ADDR ip:port] [SKIPME yes/no] | 关闭客户端连接 | |||
| CLIENT LIST | 返回客户端的信息 | O(N) | ||
| CLIENT PAUSE timeout | 暂定所有的客户端(内部交互客户端除外) | 单位为毫秒 | ||
| CLIENT REPLY ON | OFF | SKIP | 服务器是否响应客户端 | |||
| CLIENT SETNAME | 设置当前连接的名字 | O(1) | ||
| CLIENT GETNAME | 返回当前连接的名字 | O(1) |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| DISCARD | |||
| EXEC | 开始执行命令 | ||
| MULTI | 事务的开始 | ||
| UNWATCH | |||
| WATCH | 事务开始的另一种方式 |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| SLAVEOF host port | 使该服务器成为host:port服务器的从节点 |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| SYNC | 从节点从主节点同步数据 | ||
| PSYNC runid offset | 从节点从主节点同步数据 |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| CLUSTER ADDSLOTS | |||
| CLUSTER COUNT-FAILURE-REPORTS node-id | |||
| CLUSTER COUNTKEYSINSLOT slot | |||
| CLUSTER DELSLOTS slot [slot …] | |||
| CLUSTER FAILOVER [FORCE | TAKEOVER] | |||
| CLUSTER FORGET node-id | |||
| CLUSTER GETKEYSINSLOT slot count | 返回count个指定槽里的关键字的数量 | ||
| CLUSTER INFO | |||
| CLUSTER KEYSLOT key | 返回key对应的槽值 | O(N) | |
| CLUSTER MEET ip port | 将其它节点加入到集群中 | O(1) | |
| CLUSTER NODES | |||
| CLUSTER REPLICATE node-id | 设置从节点 | ||
| CLUSTER RESET [HARD | SOFT] | |||
| CLUSTER SAVECONFIG | |||
| CLUSTER SET-CONFIG-EPOCH config-epoch | |||
| CLUSTER SETSLOT slot IMPORTING | MIGRATING | STABLE | NODE [node-id] | 用于重新分片 | ||
| CLUSTER SLAVES node-id | |||
| CLUSTER SLOTS | |||
| MIGRATE host port key | “” destination-db timeout [COPY] [REPLACE] [KEYS key [key …]] | 原子操作 将key从一个数据库转移到另一个数据库 | O(N) | 在源数据库上执行DUMP+DEL 在目标数据库上执行RESTORE |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| INFO [section] | 返回服务器的信息 |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| PSUBSCRIBE pattern [pattern …] | 使客户端订阅一个或多个模式 | O(N) | |
| PUBLISH channel message | 在某个频道上发布一条消息 | O(N+M) | |
| PUBSUB | 自省命令,监测发布订阅系统的状态 | ||
| PUNSUBSCRIBE [pattern [pattern …]] | 使客户端退订一个或多个模式 | O(N+M) | |
| SUBSCRIBE channel [channel …] | 使客户端订阅一个或多个频道 | O(N) | |
| UNSUBSCRIBE [channel [channel …]] | 使客户端退订一个或多个频道 | O(N) |
| 命令 | 解释 | 时间复杂度 | 特别说明 |
|---|---|---|---|
| DUMP key | 序列化关键字指定的值 | ||
| RESTORE key ttl serialized-value [REPLACE] | 使用序列化的值创建key | ||
| SORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern]] [ASC | DESC] [ALPHA] [STORE destination] | 排序 | ||
| TYPE key | 返回key指定的值的类型,可能是string, list, set, zset, hash | O(1) | |
| OBJECT sumcommand [arguments [arguments …]] | 查看与key相关的redis对象的内部 | O(1) |
|
|
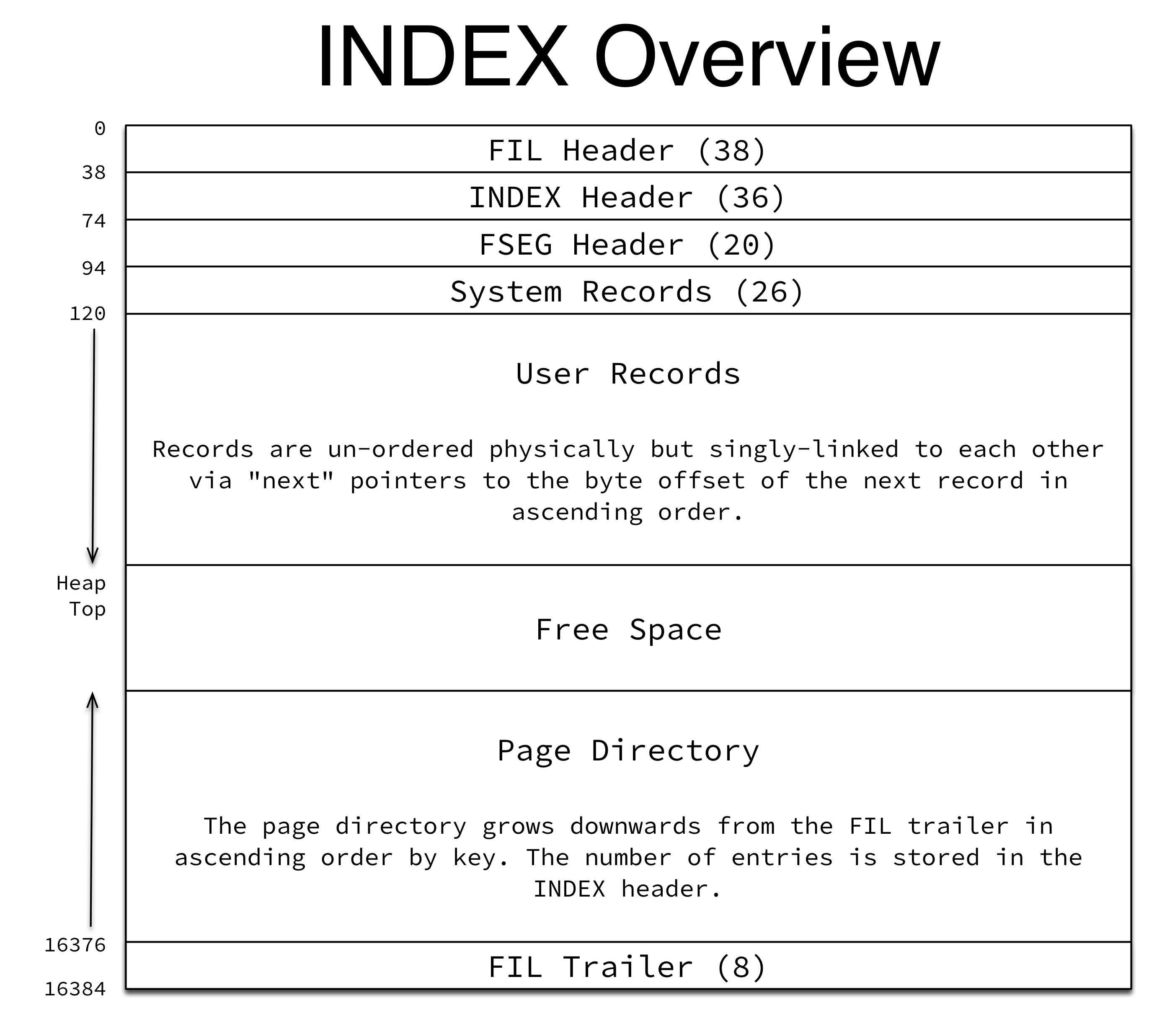
最近在学mysql,看的是《Mysql技术内幕: InnoDB存储引擎》,在读到行记录格式时,发现一个让自己无法理解的事情。于是就揪出了innodb的源码仔细研究一番,最后发现书中的语言确实会将人带入一种认识的误区,也可能是个人理解能力有问题,不说这个了,我们直接说问题。
|
|
物理文件中的内容如下:
|
|
按照书中所说,我们按照协议格式解析第一条及第二条记录如下:
|
|
但是,问题来了,0xc078+0x002b=0xc0a3,与实际的开始地址0xc0a4不符,怎么回事呢?通过看代码,原来每行记录的开始地址是从第一列数据开始,通过下面的代码依次获得后面的记录。
|
|
通过上面的分析,原来第一条记录的开始地址是0xc081,第二条记录的开始地址是0xc0ac。
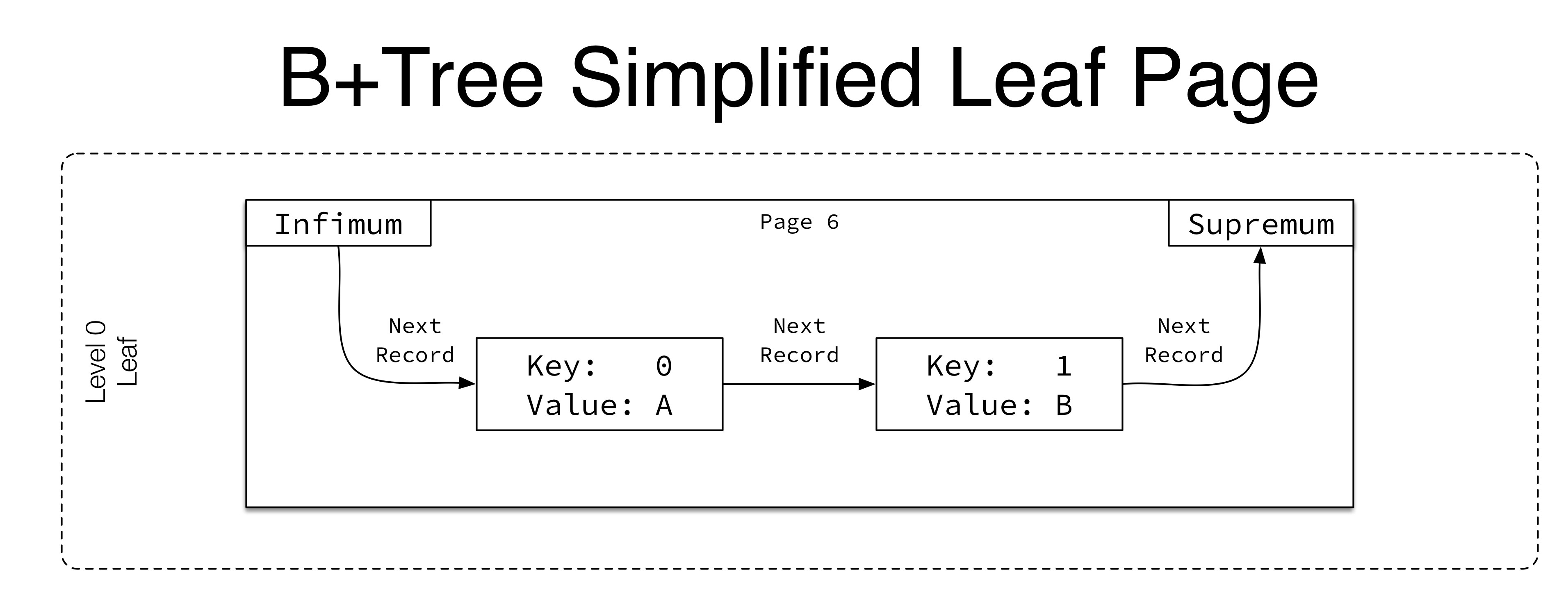
innodb通过一个单链表将页内的所有记录串联起来,如上图所示。
缺失模块。
1、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
2、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: true
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true