
java版本管理工具
mac环境设置
jenv add /Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home/
AT&T是一家美国电信公司,贝尔实验室是该公司旗下的一个实验室。实验室里有两名牛逼的哥们。他们使用B语言开发了第一个版unix。后来,其中一个哥们在B语言的基础上设计了C语言。然后,unix用C语言又重写了一遍。
BSD是unix的一个衍生分支。在这个分支上,发明了很多新技术,比如socket, ipc, vi, termcap等。
GNU是由一个哥们创建的组织。该组织的目的是要制作一个类似unix的操作系统。它拥有各种工具,编译器,各种应用,但就是缺少一个内核。Linux是另一个哥们写的类似unix的操作系统内核,但是缺少周边工具来让它发挥更大的作用。
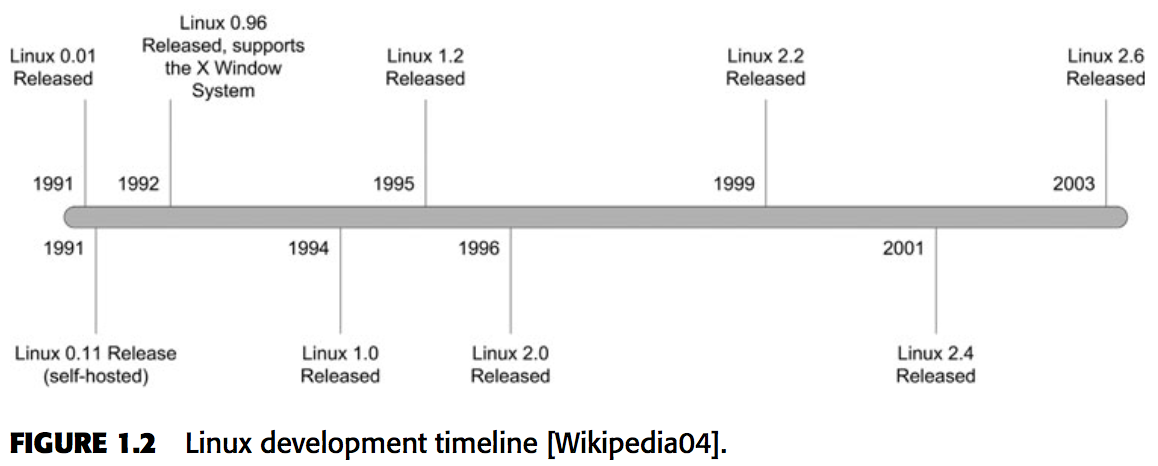

GNU/Linux是二者的组合,也就是我们平时使用的操作系统。其中,内核是Linux。shell, 编译工具链,各种实用程序和工具都是GNU软件。内核仅占整个操作系统极少的部分,大约3%。
GNU’s not UNIX. Linux’s not UNIX. GNU/Linux is UNIX.

Debian也是一个致力于创建自由操作系统的组织,但是它是在GNU/Linux的基础之上。RedHat是一家开源解决方案供应商,基于GNU/Linux.
Ubuntu是基于Debian的以桌面为主的操作系统。CentOS是基于RedHat的以服务器为主的操作系统。
以下是上面故事中的哥们,向他们致敬,如果没有他们,也就没有我们这群快乐的屌丝:



参考
最初的软件包是tar.gz,人们将自己的程序打包,然后供别人免费下载使用。使用的人下载源码之后,解压,编译,使用。随着软件的发展,可用的软件越来越多,简单的打包已经不能满足人们对软件的管理,于是出现了包管理机制。
由于linux有两大阵营,所以出现了两个包管理工具:rpm和dpkg。
rpm(RedHat Package Manager)是以RedHat为中心的包管理工具。
|
|
由于rpm不支持依赖管理,所以每次使用rpm安装软件时,如果依赖其他包,需要我们手动下载安装依赖,显而易见,这样是很不方便的,于是yum(Yellowdog Updater Modified)出现了。yum在rpm的基础之上增加了自动更新和依赖关系管理。
|
|
|
|
|
|
epel是Fedora小组维护的软件仓库,为CentOS提供默认不提供的软件包。
|
|
配置文件目录:/etc/rabbitmq/rabbitmq.config。配置文件内容格式如下:
|
|
| 配置 | 值类型 | 默认值 | 备注 |
|---|---|---|---|
| dump_log_write_threshold | int | 100 | |
| tcp_listeners | [{“ip”, port}] | [{“0.0.0.0”, 5672}] | |
| ssl_listeners | [{“ip”, port}] | 空 | |
| ssl_options | [{key, value}] | 空 | |
| vm_memory_high_watermark | 十进制百分数 | 0.4 | |
| msg_store_file_size_limit | int 字节 | 16777216 | |
| queue_index_max_journal_entries | int | 262144 |
通过运行rabbitmqctl -h可获得命名的具体使用方法。
|
|
|
|
|
|
|
|
mysql库 user表
|
|
user表中host的含义
| host | 说明 |
|---|---|
| % | 匹配所有主机 |
| localhost | 通过unix socket连接 |
| 127.0.0.1 | 通过tcp/ip, 且只能在本地连接 |
| ::1 | 支持ipv6, 同127.0.0.1 |
权限表
| 权限 | 说明 |
|---|---|
| all | 所有权限 |
| alter | |
| alter routine | |
| create | |
| create routine | |
| create temporary tables | |
| create user | |
| create view | |
| delete | |
| drop | |
| execute | |
| file | |
| grant option | |
| index | |
| insert | 可以使用create index和drop index |
| lock tables | |
| process | |
| reload | 使用flush |
| replication client | |
| replication slave | |
| select | |
| show databases | |
| show view | |
| shutdown | |
| super | |
| update | |
| usage | 无访问权限 |
|
|
|
|
|
|
ubuntu环境,系统配置文件/etc/mysql/my.conf
|
|
修改/etc/mysql/mysql.conf.d/mysqld.cnf
|
|
|
|
|
|
|
|
|
|
B树主要是为了提高硬盘的访问速度。首先,我们看下硬盘的结构:
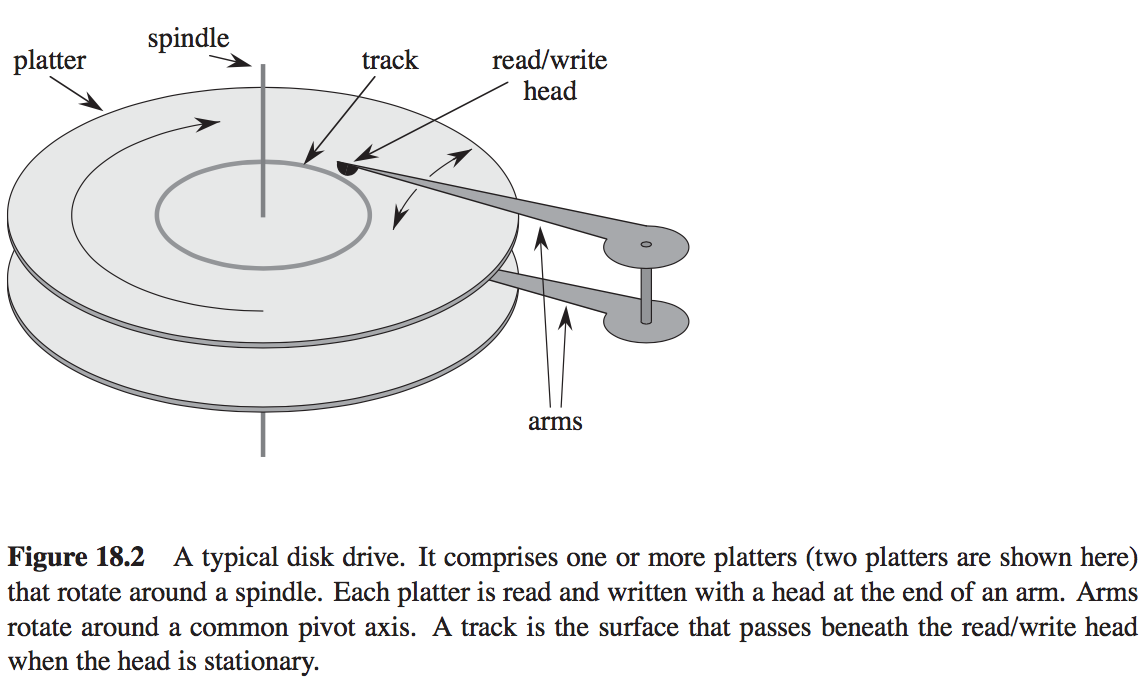
硬盘主要由中心轴(spindle),盘片(platter)、读写臂(arms)和读写头(read/write head)组成。读写臂可以在盘片上移动,当读写臂固定盘片转动时,读写头下面的部分称为磁道(track)。多个盘片只能增加磁盘的容量。
磁盘的访问是一种机械运动,主要包括盘片的旋转和读写臂的移动。磁盘的旋转速度一般在5400~15000RPM。盘片转动一圈需要的时间在8~11毫秒之间。然而,内存的访问速度是50纳秒。换言之,在我们等待某个数据转到读写头下的时间内,我们已经可以访问内存100000次了。
为了最小化机械运动的等待时间,一次硬盘访问不止读取一条数据,而是很多条。信息被分割为等大小的数据块,每块数据被称为一页。每页的数据在磁道内是连续的。每次硬盘读写一个或多个页。典型的配置是一页的数据包含$2^{11}$到$2^{14}$个字节。
由于访问硬盘数据的时间基本花费在读取磁盘的过程中,因此我们在关注程序执行时间的时候,主要关注两个指标:磁盘的访问次数和CPU的执行时间。硬盘的访问次数与每次访问磁盘时访问的页数量相关。
在典型的B树应用里,数据量太大以至于不能一次全部存储在内存里。B树算法从硬盘向内存拷贝需要的数据,拷贝内存中改变的数据到硬盘。在任何时间,B树只保存一定数量的页在内存中。因此,内存的大小不会限制B树能处理的数据的大小。
|
|
以上是对内存中对象的典型访问方式。
B树算法的运行时间主要依赖于硬盘的读写次数。因此,我们希望每次硬盘读写尽量操作更多的数据,这样可以减少硬盘的读写次数。因此,一棵B树节点的大小通常是一个完整的硬盘页的大小。一个B树节点通常包含很多关键字,B树节点的大小和关键字的大小共同限制了B树节点能拥有的子节点的数量(即分裂因子)。分裂因子越大,树的高度越低,硬盘的访问数量越少。分裂因子一般在50~2000之间。

如上图所示,一个分裂因子为1001高度为2的B树能存储十亿个关键字。由于树的根节点一直保存在内存中,因此在这课树中访问任何一个节点至多需要两次硬盘访问。
通常情况下,节点由关键字及与该关键字相关的其他信息页的指针组成。
B+树存储所有的相关信息在叶子节点,非叶子节点只存储关键字,这样使非叶子节点的分裂因子最大,降低树的高度,提高了访问速度。
B树被广泛应用在数据库的索引中,比如Mysql、MongoDB。
后续会对这些具体的应用进行分析,敬请期待!
安装node.js 此时会安装node和npm(js的包管理工具)
|
|
|
|
此时访问http://127.0.0.1:4000 如果访问成功, 恭喜安装成功
修改_confim.yml文件, 注意: 冒号后必须有空格
|
|
配置后执行如下命令
|
|
|
|
Cover
Oishi
TKL
Tinnypp
Writing
Yilia 强烈推荐
Pacman
|
|
缺失模块。
1、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
2、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: true
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true