
简介
innodb是第一个完整支持ACID事物的mysql存储引擎,行锁设计,支持MVCC,提供类似oracle风格的一致性非锁定读,支持外键,被设计用来最有效的利用内存和CPU。
内存
innodb有许多内存块,其中包括buffer pool、redo log buffer、additional memory pool。这些内存块组成了一个大的内存池,负责如下工作:
- 维护所有进程/线程需要访问的多个内部数据结构
- 缓存磁盘上的数据,方便快速读取,并且对磁盘上的文件进行修改之前在这里缓存
- 重做日志缓冲
- …
|
|
使用内存的方法: 将数据库文件按页(每页16K)读取到内存池,然后按照最近最少使用算法(LRU)来保留在内存池中的数据。对数据的修改,首先修改内存池中的数据,此时该数据为脏数据,然后再以一定的频率将脏数据刷新到磁盘。
buffer pool里的数据页类型: index page、data page、undo page、insert buffer、自适应哈希索引(adaptive hash index)、lock info、data dictionary等
redo log buffer记录重做日志信息,然后以一定的频率(每秒)将其刷新到重做日志文件。
additional mem pool记录一些其他对象的信息。
线程
innodb也有许多后台线程,默认情况下有4个IO线程、1个主线程、1个锁监控线程、1个错误监控线程。主要负责如下工作:
- 刷新内存中的数据,保证内存池中的内存缓存的是最近的数据
- 将已修改的数据刷新到磁盘文件,同时保证数据库发生异常的情况下innodb能恢复到正常运行状态
4个IO线程分别为insert buffer thread、log thread、read thread、write thread。
|
|
master thread 待看
关键特性
插入缓冲(insert buffer)
插入缓冲是为了提高对非聚集索引的操作的,首先判断非聚集索引页是否在缓冲池中,如果在,则直接插入。否则将数据放入插入缓冲区中,然后以一定的频率执行插入缓冲和非聚集索引叶子节点的合并操作。需满足如下两个条件:
- 索引是非聚集索引
- 不是唯一索引
|
|
为了插入速度的提升
双写(double write)
double write由两部分组成: 1. 内存中的doublewrite buffer,大小为2MB;另一部分是物理磁盘上共享表空间中连续的128个页,即两个区,大小同样为2M。
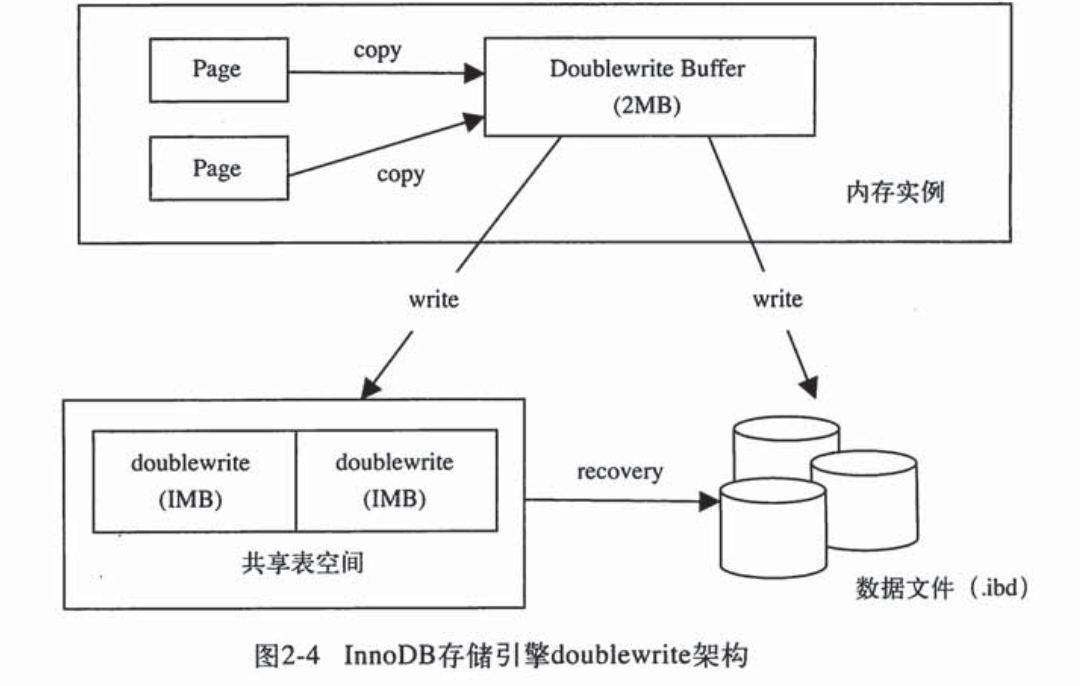
运行原理:当缓冲池中的脏页刷新时,并不直接写磁盘,而是通过memcpy函数将脏页先拷贝到内存中的doublewrite buffer,之后通过两次磁盘写操作将数据持久化到硬盘,每次写入数据量1M。第一次写到共享表空间的物理磁盘上,然后马上调用fsync函数,同步磁盘,由于页是连续的,所以执行速度很快。第二次写到各个表空间文件中,此时的写入则是离散的。
|
|
如果数据库在将页写入磁盘的过程中崩溃了,在恢复过程中,innodb引擎可以从共享表空间的doublewrite中找到该页的副本,将其拷贝到表空间里,再应用重做日志。
为了数据的安全
自适应哈希索引
自适应哈希索引不需要将整个表都建索引,innodb会自动根据访问的频率和模式来为某些页建立哈希索引。
|
|
为了查询速度的提升
启动、关闭和恢复
innodb_fast_shutdown参数决定了innodb关闭时执行的操作,默认为0。
| innodb_fast_shutdown | 含义 |
|---|---|
| 0 | 完成所有的full purge和merge insert buffer操作 |
| 1 | 不做如上操作,只刷新缓冲池中的脏数据到磁盘 |
| 2 | 不做如上操作,只将日志写入到日志文件 |
innodb_force_recovery参数决定了innodb启动时执行的操作,默认为0。
| innodb_force_recovery | 含义 |
|---|---|
| 0 | 执行所有的恢复操作 |
| 1 | 忽略检查到的corrupt页 |
| 2 | 阻止主线程的执行,如主线程需要执行full purge操作,会导致crash |
| 3 | 不执行事务回滚操作 |
| 4 | 不执行插入缓冲的合并操作 |
| 5 | 不查看撤销日志,会将未提交的事务视为已提交 |
| 6 | 不执行回滚的操作 |
文件
参数文件
|
|
日志文件
错误日志
对mysql的启动、运行、关闭过程进行了记录。
|
|
二进制日志
待看
|
|
慢查询日志
主要用来优化sql查询。
|
|
表结构定义文件
以frm为后缀名结尾的文件记录了表的结构定义。该文件还用来存放试图的定义。
innodb存储引擎文件
重做日志文件
ib_logile0和ib_logfile1是innodb存储引擎的重做日志文件,主要用来记录innodb引擎的事务日志。
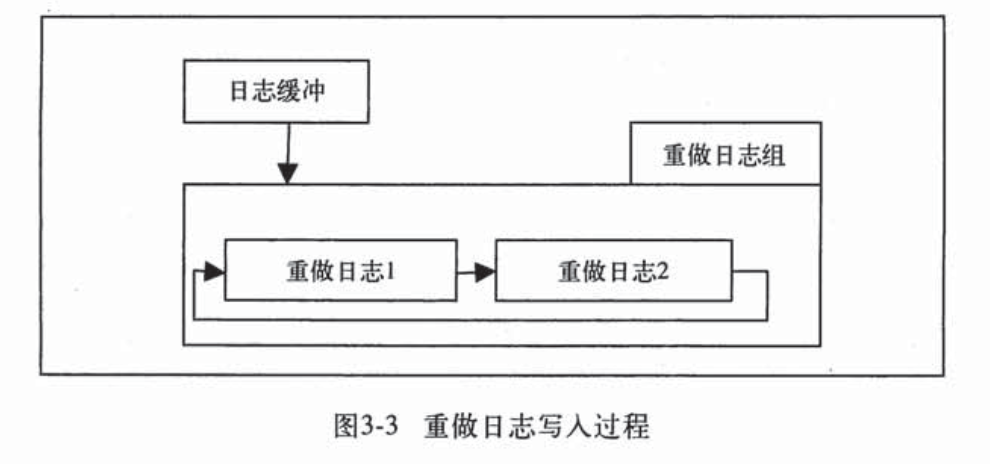
如图所示,重做日志首先写入重做日志缓冲区中,然后以一定的频率刷新到磁盘。主线程每秒将重做日志缓冲写入到磁盘的重做日志文件,不论事务是否已提交。innodb_flush_log_at_trx_commit参数决定了在事务提交时,对重做日志的处理。
| innodb_flush_log_at_trx_commit | 含义 |
|---|---|
| 0 | 等待主线程每秒的刷新 |
| 1 | commit时将重做日志缓冲同步到磁盘 |
| 2 | commit时将重做日志异步写到磁盘 |
|
|
表空间文件
ibdata1即为默认的表空间文件。innodb_file_per_table参数可设置每张表一个表空间文件,单独的表空间文件以ibd为后缀,这些文件只记录了该表的数据、索引和插入缓冲等信息,其他信息还是要存放到默认的表空间文件中。
|
|
表
innodb存储引擎表中,每张表都有个主键,如果在创建表时没有显式的定义主键(primary key),则会按如下方式选择或创建主键:
- 表中是否有非空的且为唯一的列,若有,则该列即为主键
- 不符合上述条件,则自动创建一个6个字节大小的指针
逻辑存储结构
所有数据被逻辑的存放在一个空间中,该空间被称为表空间(tablespace)。表空间又由段(segment)、区(extent)、页(page)组成。如下图所示:
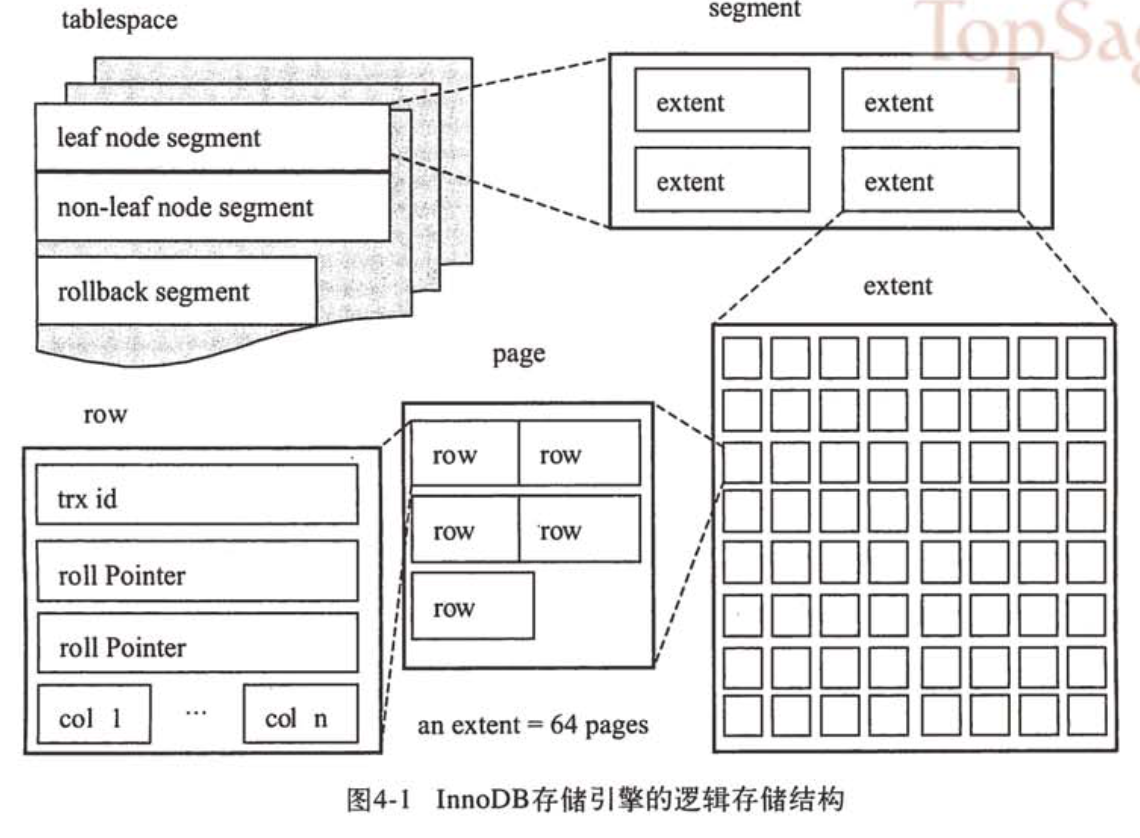
常见的段有数据段、索引段、回滚段等,其中数据段即为B+树的叶节点,索引段即为B+树的非叶节点。
区是由64个连续的页组成的,每个页的大小为16KB,即每个区的大小为1MB。
每页可容纳的记录数(即行数)为200~16KB/2之间。
物理存储结构
若将innodb_file_per_table设置为on,则每个表将独立的产生一个表空间文件,以ibd结尾,数据、索引、表的内部数据字典信息都将保存在这个单独的表空间文件中。表结构定义文件后缀为frm。
InnoDB行记录格式
mysql5.1之后,有两种存放行记录的格式: Compact和Redundant,其中Compact是新格式。
|
|
|
|
| 名称 | 大小(bit) | 含义 |
|---|---|---|
| () | 1 | 未知 |
| () | 1 | 未知 |
| deleted_flag | 1 | 该行是否已被删除 |
| min_rec_flag | 1 | 若该记录是预先被定义为最小记录则为1 |
| n_owned | 4 | 该记录拥有的记录数 |
| heap_no | 13 | 索引堆中该记录的排序记录 |
| record_type | 3 | 记录类型 000:普通 001:B+树节点指针 002:Infinum 003: Supermum 1xx=保留 |
| next_recorder | 16 | 页中下一条记录的相对位置 |
|
|
InnoDB数据页结构
InnoDB数据页格式如下图所示:
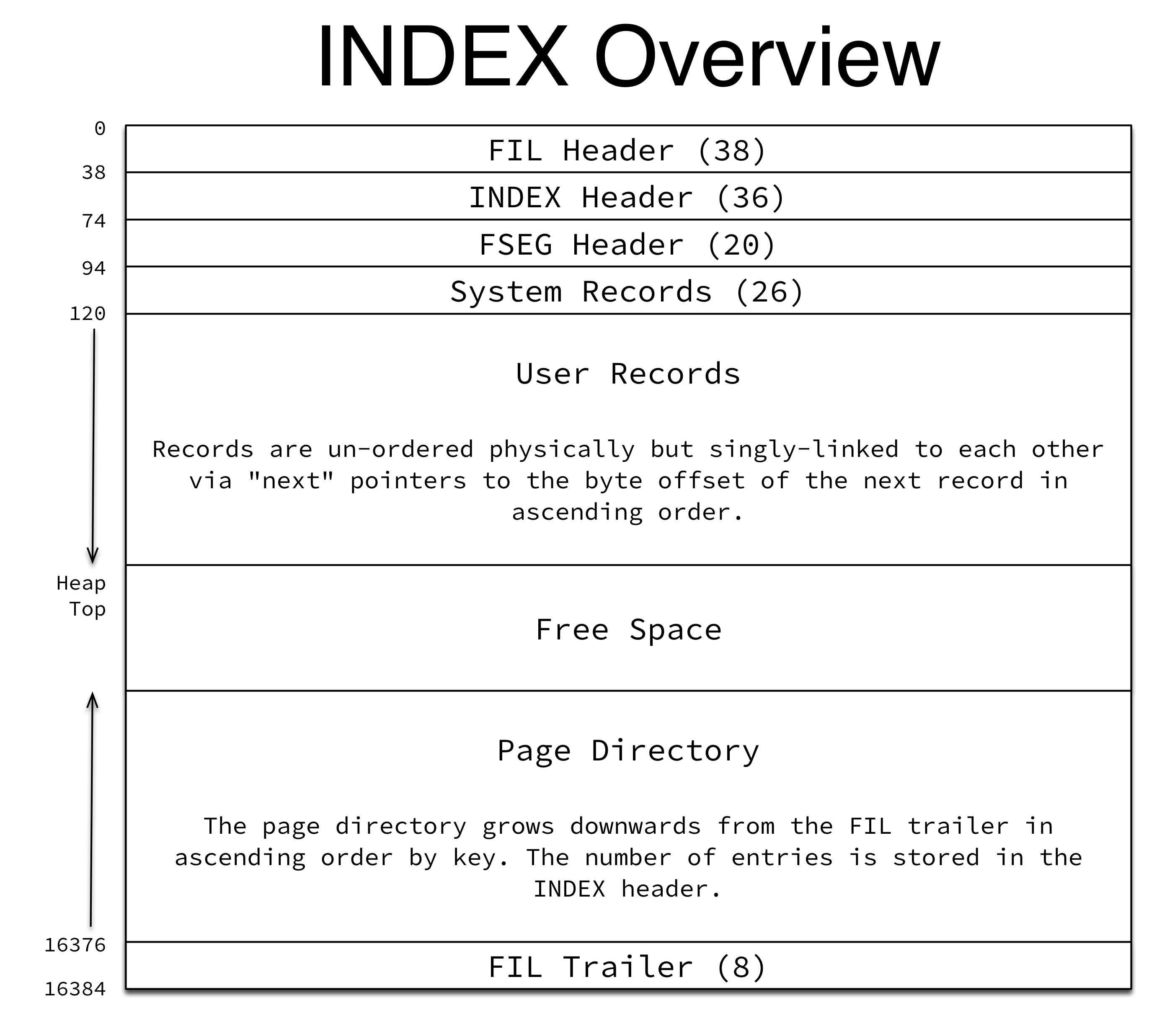
File Header包含如下字段:
| 字段 | 大小(字节) | 含义 |
|---|---|---|
| FIL_FILE_PAGE_OR_CHKSUM | 4 | 目前为checksum值 |
| FIL_PAGE_OFFSET | 4 | 页的偏移值? |
| FIL_PAGE_PREV | 4 | 上一页 |
| FIL_PAGE_NEXT | 4 | 下一页 |
| FIL_PAGE_LSN | 8 | 该页最后被修改的日志序列位置LSN(Log Sequence Number) |
| FIL_PAGE_TYPE | 2 | 页的类型 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 | 该值只在数据文件的一个页中定义,代表文件至少被更新到了该LSN值 |
| FIL_PAGE_ARCH_LOG_ON_OR_SPACE_ID | 4 | 该页属于哪个表空间 |
页类型有如下几种:
| 名称 | 十六进制 | 解释 |
|---|---|---|
| FIL_PAGE_INDEX | 0x45BF | B+树叶子节点 |
| FIL_PAGE_UNDO_LOG | 0x0002 | Undo Log 页 |
| FIL_PAGE_INODE | 0x0003 | 索引节点 |
| FIL_PAGE_IBUF_FREE_LIST | 0x0004 | Insert Buffer 空闲列表 |
| FIL_PAGE_TYPE_ALLOCATED | 0x0000 | 该页为最新分配 |
| FIL_PAGE_IBUF_BITMAP | 0x0005 | Insert Buffer位图 |
| FIL_PAGE_TYPE_SYS | 0x0006 | 系统页 |
| FIL_PAGE_TYPE_TRX_SYS | 0x0007 | 事务系统数据 |
| FIL_PAGE_TYPE_FSP_HDR | 0x0008 | File Space Header |
| FIL_PAGE_TYPE_XDES | 0x0009 | 扩展描述页 |
| FIL_PAGE_TYPE_BLOB | 0x000A | BLOB页 |
Index Header包含字段如下:
| 字段 | 大小(字节) | 解释 |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2 | 在page directory中的slots数 |
| PAGE_HEAP_TOP | 2 | 空闲空间开始位置的偏移量 |
| PAGE_N_HEAP | 2 | 堆中的记录数 |
| PAGE_FREE | 2 | 指向空闲列表的首指针 |
| PAGE_GARBAGE | 2 | 已删除记录的字节数 即行记录中,delete flag为1的记录大小的总和 |
| PAGE_LAST_INSERT | 2 | 最后插入记录的位置 |
| PAGE_DIRECTION | 2 | 最后插入的方向 |
| PAGE_N_DIRECTION | 2 | 一个方向连续插入记录的数量 |
| PAGE_N_RECS | 2 | 该页中记录的数量 |
| PAGE_MAX_TRX_ID | 8 | 修改当前页的最大事务ID,注意该值仅在secondary index中定义 |
| PAGE_LEVEL | 2 | 当前页在索引树中的位置 0x00代表页节点 |
| PAGE_INDEX_ID | 8 | 当前页属于哪个索引ID |
FSEG Header包含字段如下:
| 字段 | 大小(字节) | 解释 |
|---|---|---|
| PAGE_BTR_SEG_LEAF | 10 | B+树的叶节点中,文件段的首指针位置 |
| PAGE_BTR_SEG_TOP | 10 | B+树的非叶节点中,文件段的首指针位置 |
System records中包含的字段:
infimum和supremum记录?
User records即实际存储行记录的内容。
FreeSpace空闲链表,同样是链表数据结构,当一条记录被删除后会被加入空闲链表中。
File Traier的作用是保证页的完整性,其中包含的字段如下:
| 字段 | 大小(字节) | 解释 |
|---|---|---|
| FIL_PAGE_END_LSN | 8 | 前4个字节代表该页的checksum值,后4个字节与File Header中的FIL_PAGE_LSN相同 |
索引
innodb支持两种索引: B+树索引和哈希索引。
哈希索引
innodb引擎支持的哈希索引是自适应的,会根据表的使用情况自动生成哈希索引,不能人工干预。最终目的是加速对内存数据即缓存的查找。
|
|
B+树索引
B+树索引能找到的只是被查找数据行所在的页,将页加载到内存后再通过二分查找,最后得到查找的数据。最终目的是加速对磁盘即数据库文件的查找。
插入操作
插入操作的三种情况
| leaf page full | index page full | operations |
|---|---|---|
| No | No | 直接将记录插入页节点 |
| Yes | No | 1. 拆分leaf page 2. 将中间节点放入index page中 3. 小于中间节点的记录放左边 4. 大于等于中间节点的记录放右边 |
| Yes | Yes | 1. 拆分leaf page 2. 小于中间节点的记录放左边 3. 大于中间节点的记录放右边 4. 拆分index page 5. 小于中间节点的记录放左边 6. 大于中间节点的记录放右边 7. 中间节点放入上一层index page |
页的拆分意味着磁盘的操作,为了尽量避免磁盘操作,使用旋转来避免页拆分。
删除操作
B+树使用填充因子(fill factor)控制树的删除变化,50%是填充因子的最小值。
| leaf page below fill factor | index page below fill factor | oprations |
|---|---|---|
| No | No | 直接将记录从叶节点删除,如果该节点还是index page节点,则用该节点的右节点替代 |
| Yes | No | 合并页节点及其兄弟节点,同时更新index page |
| Yes | Yes | 1. 合并叶节点机器兄弟节点 2. 更新index page 3. 合并index page及其兄弟节点 |
聚集索引和非聚集索引
innodb存储引擎表中数据按照主键顺序存放。
聚集索引(clustered index)就是按照表中主键构造一个B+树,并且叶节点中存放着整张表的行记录数据,因此叶节点也是数据页。
数据页通过双向链表维护,页中的记录也通过双向链表维护。
非聚集索引(secondary index)是按照指定的关键字构造的一个B+树,并且叶节点存放的是行记录的主键。
如果在一个高度为3的非聚集索引树上查找数据,那么首先需要通过3次磁盘IO从非聚集索引找到指定主键。如果聚集索引高度同样为3,那么还需要通过3次磁盘IO从聚集索引找到要查找的数据。
预读取
顺序预读取: 一个区(由64个页组成)中多少页被顺序访问时,innodb引擎会读取下一个区的所有页。
|
|
辅助索引
联合索引
值得关注的地方
- 对于索引的添加和删除操作,mysql数据库先创建一张临时表,然后把数据导入临时表,删除原表,然后将临时表重命名为原来的表名,所以对于大表,此操作极为耗时。
- 从版本innodb plugin开始,支持一种称为快速索引创建方法,仅限于非聚集索引。
- 索引的使用原则: 高选择性和取出表中少部分数据。
- 即使访问的是高选择性字段,但是由于查询命中的数据占表中大部分(经验值20%)数据时,此时查询优化器也会不走索引,而执行全表扫描。
锁
mysql提供了表级锁,表级锁并发性不高,表级锁分为两类:
- 共享锁(S Lock) 允许事务读该表
- 排它锁(X Lock) 允许操作该表
为了提高并发性,innodb存储引擎提供了行级锁,行级锁分两种:
- 共享锁(S Lock) 允许事务读一行数据
- 排它锁(X Lock) 允许事务删除或更新一行数据
innnodb引擎支持多粒度锁定,即在一个表上可以加表锁也可以加行锁。
假设现在有两个事务t1和t2,其中t1在x表的某一行上加锁,这时,t2想对x表加锁,在加锁之前,t2需要遍历所有的行,检查有没有行锁,很明显,这样效率是不高的。
为了支持这种多粒度锁定,又为了提高程序的速度,引擎引入了另一种锁,叫意向锁。意向锁是表级别的锁。支持两种意向锁:
- 意向共享锁(IS Lock) 事务想要获得一个表中某几行的共享锁
- 意向排它锁(IX Lock) 事务想要获得一个表中某几行的排它锁
还是刚才的事例,有了意向锁之后,t1在x表的某一行加锁之前,需要对x表加一个意向共享锁,然后才能在某一行加锁。这样当t2想对x表加锁时,只要检查该表有没有意向锁就好了,性能得到明显的提高。
查看当前数据库的请求和锁的情况
|
|
多版本并发控制(MVCC)
|
|
锁定算法:
- Record Lock: 单个行记录上的锁
- Gap Lock: 间隙锁,锁定一个范围,但不包含记录本身
- Next-key Lock: Record Lock + Gap Lock,锁定一个范围,并且包含记录本身
| 事务隔离级别 | 非锁定的一致性读 | 锁定算法 |
|---|---|---|
| Read Uncommitted | ||
| Read Committed | 总是读取被锁定行的最新一份快照数据 | |
| Repeatable Read(默认) | 总是读取事务开始时的行快照数据 | Next-key Lock |
|
|
自增长与锁
自增长插入分为三类:
- Simple Inserts: 能确定插入行数的插入
- Bulk Inserts: 不能确定插入行数的插入
- Mixed-mode Inserts: 插入的数据中一部分值是自增长的,一部分是确定的
|
|
| innodb_autoinc_lock_mode | 解释 |
|---|---|
| 0 | 通过表锁的AUTO-INC Locking方式 |
| 1 | 对于Simple Inserts通过互斥量 对于Bulk Inserts通过表锁的AUTO-INC Locking方式 |
| 2 | 通过互斥量 |
使用锁的问题
丢失更新
故事如下:
- 事务T1查询一行数据
- 事务T2查询一行数据
- 事务T1修改这行记录,更新数据库并提交
- 事务T2修改这行记录,更新数据库并提交
这样,事务T1的修改被事务T2的修改给覆盖了,事务T1的更新丢失了。
解决方案: 在查询的时候使用”select … for update”这样的查询语句,这样就会对该行记录加一个排它锁,其他的所有操作都会被阻塞。
脏读
脏读值得是在不同的事务下,可以读到另外事务未提交的数据。
不可重复读
不可重复读(幻读)指由于别的事务的修改,导致同一事务内对同一数据的多次读取结果不一致,一般是插入了新的数据。
阻塞
|
|
死锁
死锁发生时会回滚一个事务。
心得体会
在事务隔离级别为Read Committed下
- 读取的时候,使用多版本并发控制,不涉及锁的操作,每个事务读取该读取的版本,事务之间不存在同步问题,除非显式加锁。
- 更新的时候,会在该行显式加X锁,其他事务对该行的操作需要等待该锁的释放。
- 插入的时候,会导致幻读。
- 删除的时候,没有next-key lock锁保护。
在事务隔离级别为Repeatable Read下
- 读取的时候,使用多版本并发控制,不涉及锁的操作,每个事务读取该读取的版本,事务之间不存在同步问题,除非显式加锁。
- 更新的时候,会在该行显式加X锁,其他事务对该行的操作需要等待该锁的释放。
- 插入的时候,不会导致幻读。
- 删除的时候,会有next-key lock锁保护。
事务
ACID特性:
- 原子性(atomicity) 整个事务不可分割,要么成功,要么回到原始状态
- 一致性(consistency) 事务开始前和结束后,完整性约束不被破坏?
- 隔离性(isolation) 事务之间互不影响
- 持久性(durability) 结果的持久化保存
innodb的隔离性通过锁实现,其它三个属性原子性、一致性、持久性通过redo和undo来实现。
redo
事务日志通过redo日志文件和日志缓冲来实现。
- 当事务开始时,会记录该事务的一个LSN(Log Sequence Number)
- 当事务执行时,会往日志缓冲里插入事务日志
- 当事务提交时,必须将日志缓冲写入文件(innodb_flush_log_at_trx_commit=1)
undo
当事务需要回滚时,利用的就是这个日志。
事务控制语句
| 语句 | 含义 |
|---|---|
| start transaction or begin | 显式的开启一个事务 |
| commit or commit work | 提交一个事务 |
| rollback or rollback work | 回滚一个事务 |
| savepoint identifier | 在事务中创建一个保存点 |
| release savepoint identifier | 删除一个事务的保存点 |
| rollback to identifier | 回滚到一个保存点 |
| set transaction | 设置事务隔离级别 |
备注:
commit work在不同设置下的含义:
| completion_type | 等价于 | 含义 |
|---|---|---|
| 0 | commit | 简单提交一个事务 |
| 1 | commit and chain | 完成后会开启另一个事务 |
| 2 | commit and release | 事务提交后会自动断开与服务器的连接 |
rollback work与commit work类似。
隐式提交的sql语句
自动提交模式下,执行一条sql语句后会立即执行commit动作。其他一些DDL语句也会自动提交。
事务隔离级别
- read uncommitted
- read committed
- repeatable read
- serializable
innodb在repeatable read隔离级别下,通过next-key lock锁的算法,避免了幻读的产生,与serializable隔离级别等效。
在seriablizable隔离级别下,innodb引擎会对每个select语句后自动加上lock in share mode,即给每个读取加一个共享锁。
二进制日志格式有两种: statement和row。statement格式的是sql语句的记录,row格式的是对行的记录。
分布式事务
备份与恢复
性能调优
参考
- MySQL技术内幕: InnoDB存储引擎