
redis设计的主旨: 简单 高效
数据结构与对象
redis中一切皆对象,共包含5种对象,分别为字符串对象(string object)、列表对象(list object)、哈希对象(hash object)、集合对象(set object)、有序集合对象(sorted set object)。
数据结构
简单动态字符串
|
|
与C字符串的比较:
- 通过len字段,获取字符串长度的时间复杂度为O(1)
- 通过len字段,杜绝了缓冲区溢出问题
- 通过预分配策略和惰性空间释放策略避免了频繁的内存重分配
- 二进制安全
- 通过保留最后一个字符为空字符,可以复用C的字符串库函数,但是前提是字符串中不包含空字符,否则处理出错
双向列表
|
|
通过使用指定value的值为void*和dup、free、match可以实现多态链表。
哈希表
|
|
MurmurHash算法
跳跃表
实现有序集合的底层数据结构之一是跳跃表。当有序集合包含的元素数量比较多,又或者有序结合中元素的成员是比较长的字符串时,redis就会使用跳跃表作为有序集合键的底层实现。
跳跃表支持平均O(lgN),最坏O(N)的时间复杂度。大部分情况下,跳跃表的性能可以和平衡树相媲美,又因为跳跃表的实现比平衡树简单,所以很多程序使用跳跃表来代替平衡树。
|
|
根据幂次定律生成层数。
整数集合
实现集合的底层数据结构之一是整数集合。当一个集合只包含整数元素,并且这个集合的元素数量不多时,redis就会使用整数集合作为集合的底层实现。
|
|
升级:每当添加一个新元素,并且新元素比所有现有元素的类型都要长时整数集合需要先进行升级,然后才能将新元素添加到整数集合里面。
只有升级没有降级
压缩列表
压缩列表是列表和哈希的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么是小整数要么是长度比较短的字符串,那么redis就会使用压缩列表作为列表的底层实现。当一个字典,只包含少量键值对,并且每个键值对的键和值要么是小整数要么是长度比较短的字符串,那么redis就会使用压缩列表作为字典的底层实现。
|
|
- 压缩列表是一种为节约内存而开发的顺序型数据结构
- 压缩列表被用作列表和字典的底层实现之一
- 压缩列表可以包含多个节点,每个节点可以保存一个字节数组或整数值
- 添加新节点到压缩列表或从压缩列表中删除节点,可能会引发连锁更新操作,但这种操作出现的几率并不高
对象
redis有一个对象系统,该系统包括字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象。每种对象至少用到了一种我们之前介绍的数据结构。
redis执行命令前,根据对象的类型来判断一个对象是否可以执行给定的命令。redis可以在不同的场景下,为同样的对象选择不同的数据结构,从而达到最高的使用效率。
redis实现了基于引用计数技术的内存回收机制,且通过引用计数技术实现了对象共享机制。
对象还带有时间信息,该信息用于计算键的空转时长,当服务器启用maxmemory时,空转时长长的那些键优先被回收。
|
|
type的取值
| 类型常量 | 对象的名称 |
|---|---|
| REDIS_STRING | 字符串对象 |
| REDIS_LIST | 列表对象 |
| REDIS_HASH | 哈希对象 |
| REDIS_SET | 集合对象 |
| REDIS_ZSET | 有序集合对象 |
对于redis保存的键值对来说,键总是一个字符串对象,而值可以是字符串对象、列表对象、哈希对象、集合对象、有序集合对象。
encoding的取值
| 类型常量 | 底层数据结构 |
|---|---|
| REDIS_ENCODING_INT | long类型的整数 |
| REDIS_ENCODING_EMBSTR | embstr编码的简单动态字符串 |
| REDIS_ENCODING_RAW | 简单动态字符串 |
| REDIS_ENCODING_HT | 哈希表 |
| REDIS_ENCODING_LINKEDLIST | 双向链表 |
| REDIS_ENCODING_ZIPLIST | 压缩列表 |
| REDIS_ENCODING_INTSET | 整数集合 |
| REDIS_ENCODING_SKIPLIST | 跳跃表 |
每种类型至少使用了两种不同的编码,以下是不同类型和编码的对象
| 类型 | 编码 | 使用条件 |
|---|---|---|
| REDIS_STRING | REDIS_ENCODING_INT | 保存的是整数值,且可以使用long类型存储 |
| REDIS_STRING | REDIS_ENCODING_EMBSTR | 字符串的长度小于等于32字节 |
| REDIS_STRING | REDIS_ENCODING_RAW | 字符串的长度大于32字节 |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST | 1. 所有字符串长度都小于64字节 2. 保存的元素数量小于512个 |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST | 违反以上两条的任意一条则使用该编码 |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST | 1. 所有键值对的键和值得字符串长度都小于64字节 2. 保存的键值对的数量小于512个 |
| REDIS_HASH | REDIS_ENCODING_HT | 违反以上两条的任意一条则使用该编码 |
| REDIS_SET | REDIS_ENCODING_INTSET | 1. 保存的所有元素都是整数值 2. 保存的元素数量不超过512个 |
| REDIS_SET | REDIS_ENCODING_HT | 违反以上两条的任意一条则使用该编码 |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST | 1. 保存的所有元素的长度都小于64字节 2. 保存的元素数量小于128个 |
| REDIS_ZSET | REDIS_ENCODING_SKIPLIST | 违反以上两条的任意一条则使用该编码 |
|
|
类型检查与命令多态
类型检查通过redisObject结构的type属性实现。
内存回收
对象共享
redis服务启动的时候,会自动创建一万个字符串对象,这些对象包括了从0到9999的所有整数值。
好问题: 为什么redis不共享包含字符串的对象?
- 如果共享对象是保存整数值的字符串对象,那么验证操作的复杂度是O(1)
- 如果共享对象是保存字符串值得字符串对象,那么验证操作的复杂度是O(N)
- 如果共享对象是包含了多个值(或者对象)的对象,比如列表对象或者哈希对象,那么验证操作的复杂度是O($N^2$)
超时机制
redis里面的超时时间是以unix时间戳(2.6之后是毫秒)的形式保存的。过期的精度在0~1毫秒之间。
redis里key的过期方式有两种: 1.被动过期 2.主动过期
被动过期方式: 当客户端尝试访问一个key时,检查这个key是否超时。
主动过期方式: redis会每隔一段时间检查过期key集合里面的key是否超时。
定时删除方式: 在设置键的过期时间的同时,创建一个定时器(timer),让定时器在键的过期时间来临时,立即执行对键的删除操作。
redis主动检查过期的频率为每秒10次:
- 从过期的key集合里面随机抽取20个进行测试
- 删除所有过期的key
- 如果过期的key超过25%,则再从第一步开始
在集群之间,对于过期的key,由主节点向从节点发送DEL操作,从而保证一致性问题。但是从节点也保存过期信息,这样当从节点被选举为主节点时,也可以执行过期操作。
数据库
|
|
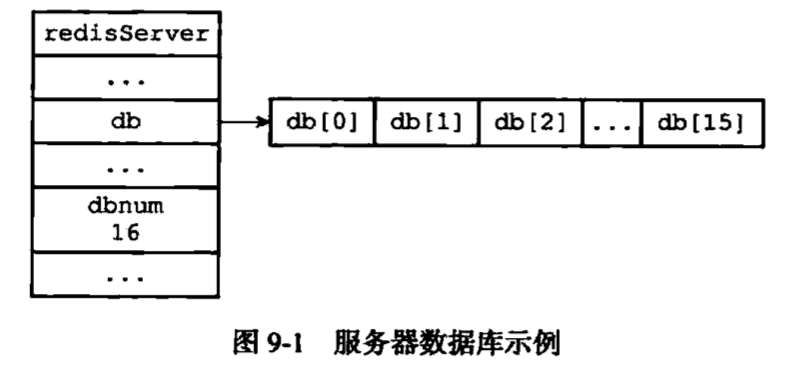
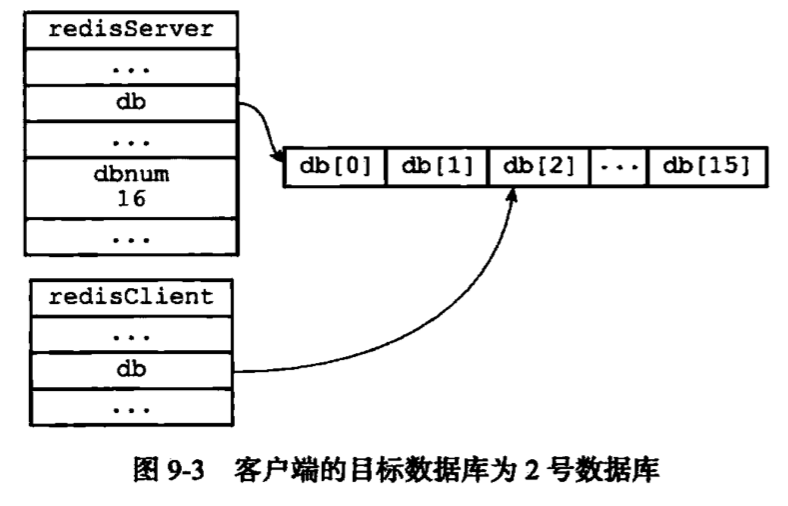
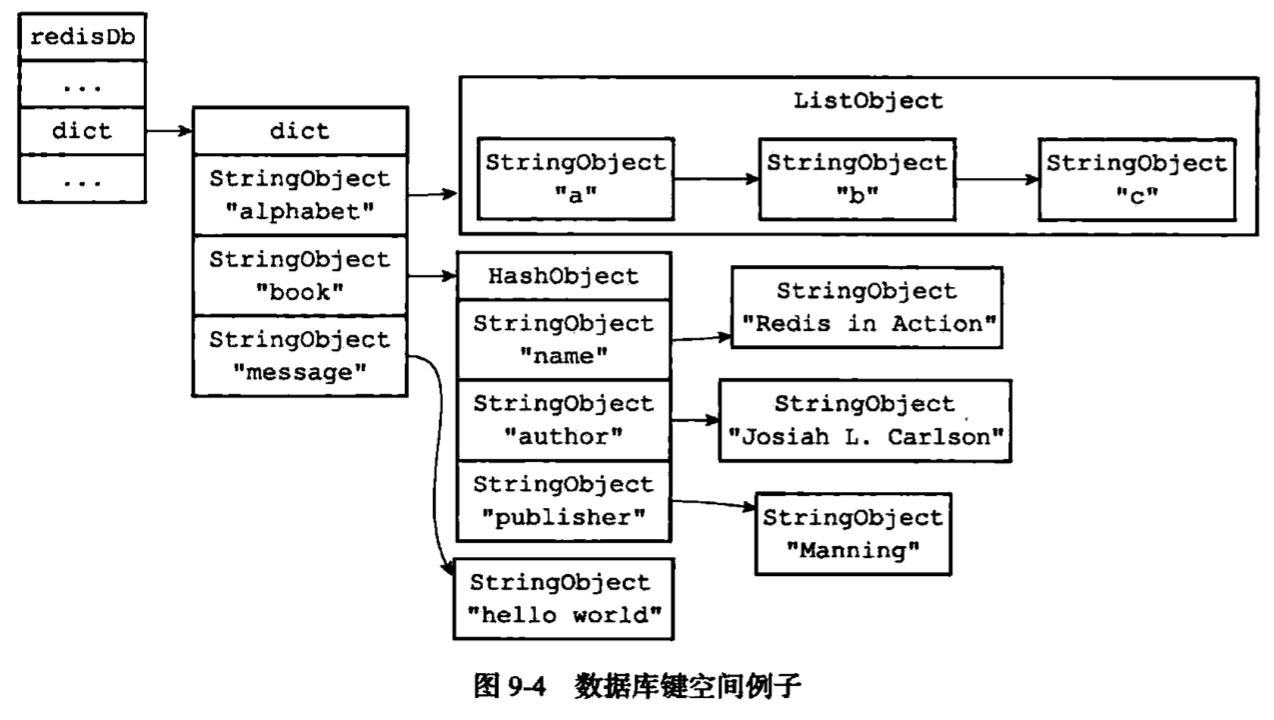
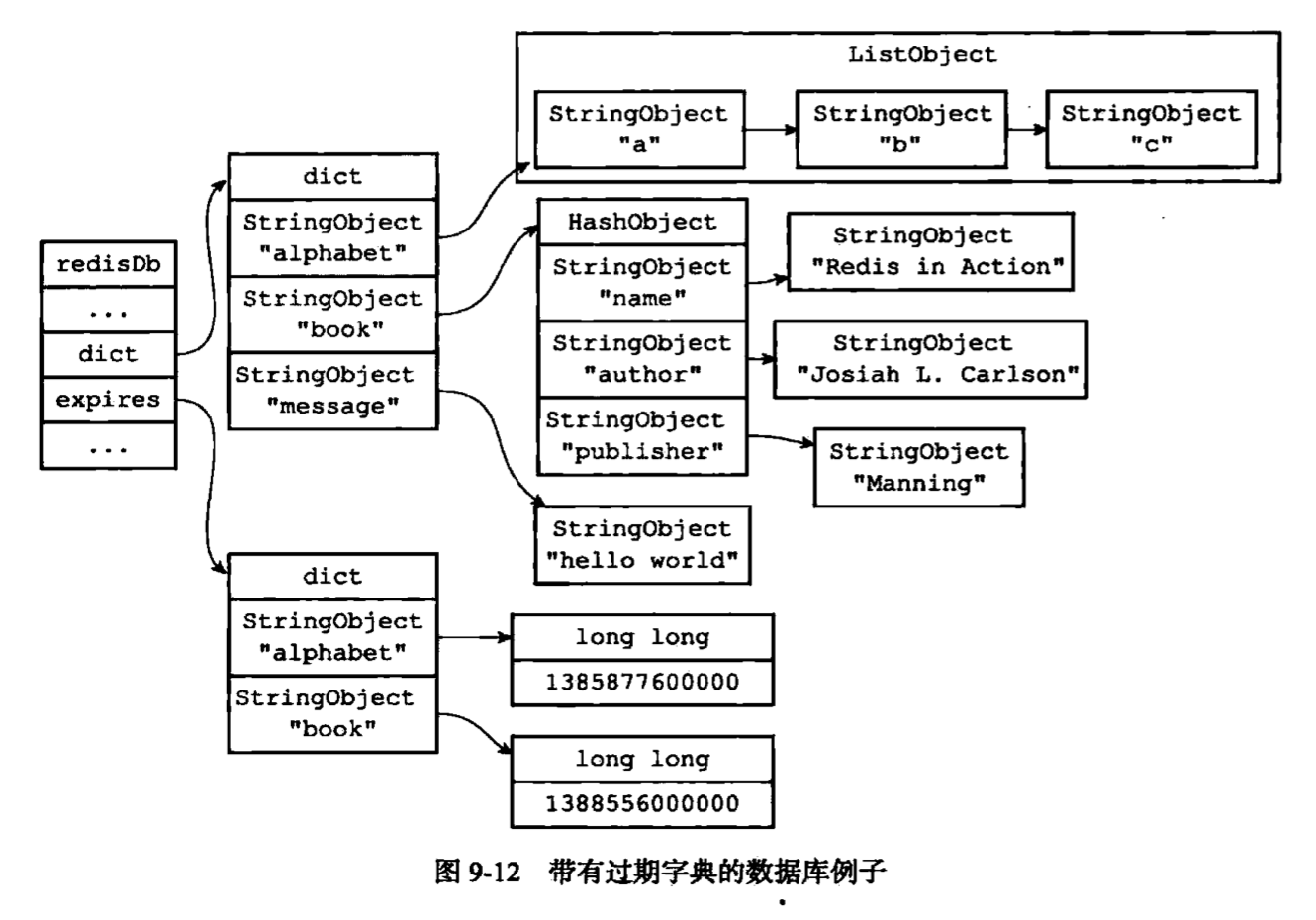
持久化
redis有两种持久化方式和: RDB持久化和AOF持久化。
RDB持久化方式通过将数据库中的所有键值对持久化到磁盘的方式完成。AOF持久化方式通过记录修改命令来记录数据库的状态。
|
|
RDB持久化
RDB持久化有两种触发方式:
- 手动触发: BGSAVE和SAVE
- 自动触发: save配置
|
|
AOF持久化
AOF持久化分为三个部分: 命令追加、文件写入、文件同步
随着服务器的运行,AOF的体积会越来越大,所以需要对AOF文件进行重建。AOF文件重建原理如下:通过添加对数据库中现有键值对的重建命令而完成。
redis创建一个子进程在后台完成AOF重建工作。由于主进程还在处理客户端的请求,所以会造成重建的AOF文件与实际数据库状态不一样。redis新增了一个AOF重建缓冲区,将重建过程中所有的命令写入到该缓冲区,待重建完成后,子进程向父进程发送信号,父进程收到信号后将该缓冲区的内容追加到AOF重建文件中,然后原子的替换原来的AOF文件。
事件
redis服务器是一个事件驱动程序,处理的事件包含两大类: 文件事件和时间事件。
文件事件
文件事件就是对网络IO的一种抽象。
| 网络IO | 文件事件 |
|---|---|
| accept | READABLE |
| read | READABLE |
| close | READABLE |
| write | WRITABLE |
时间事件
- 定时事件: 让一段程序在指定的时间之后执行一次。
- 周期性事件: 让一段程序每个一定时间就执行一次。
redis通过程序的返回值来区分定时事件和周期性事件。返回值为下次该函数执行的间隔时间。(该方法可以借鉴)
客户端与服务器
客户端
|
|
redis中的客户端有两种: 真客户端和伪客户端。其中,伪客户端用于载入AOF文件或执行lua脚本中包含的redis命令。
服务器
|
|
redis通过周期性的执行serverCon函数来维持服务器的状态。
redis在服务器启动的时候会创建一些共享对象,比如”OK”, “ERR”, 1到10000的字符串对象。(这种技术在很多地方都可见到,比如jvm里)
主从复制
当slaveof命令执行完毕后,从节点会向主节点发送PSYNC命令,如果是初次同步,则执行完整重同步(full resynchronization),主节点生成RDB文件,然后传输给从节点,从节点载入RDB文件。若载入RDB文件期间,主节点有写操作,则主节点将命令传播给从节点,使主从一致。若断线重连后,则执行部分重同步(partial resynchronization),主机点只将从节点断线期间执行的写操作发送给从节点,使主从一致。
|
|
主从复制的实现:
- 设置主服务器的地址和端口
- 建立连接
- 发送PING命令
- 身份验证
- 发送端口信息
- 同步
- 命令传播
sentinel(哨兵节点)
sentinel(哨兵节点)是redis的高可用解决方案。
|
|
节点之间的连接
当启动sentinel节点后,sentinel与主节点建立如下连接:
- 命令连接
- 订阅连接
sentinel从主节点获取从节点信息后,也建立以上两个连接。
其他监控主节点的sentinel也对主节点和从节点建立以上连接。sentinel会通过订阅连接向主节点发送消息,其它订阅了该主节点的sentinel节点收到消息后可得知监视同一主节点的所有其它所有sentinel节点。
sentinel节点之间会互相建立命令连接。
判断主节点失效的机制
当一个主节点对于一个sentinel节点不可达down-after-milliseconds毫秒后,该sentinel节点就认为该主节点主观下线。
然后询问其它监视该主节点的sentinel节点,若超过预设置的值则认为该节点客观下线。随后进行新主节点的选举。
节点选举
首先,简单介绍下redis的sentinel的概念,然后通过一个简单的例子来说明redis的sentinel的运行机制。
- 一个主节点下可以有多个从节点
- 一个主节点可以被多个sentinel节点监视
- 当主节点被判断为客观下线状态时,会有两个选举过程
- 第一个选举过程是从所有监视该主节点的sentinel里产生领头sentinel,第二个选举过程是从所有的从节点中产生主节点
这个选举机制和总统选举很像。总统相当于主节点,总统胡选人相同于从节点,各大有钱有势的集团相当于sentinel。当总统换届时,各大集团选举出一个领头的集团,该领头的集团从总统候选人中选出一个新的总统。
redis采用了Raft算法保证各个节点达成共识。
集群
|
|
redis集群思想: redis的集群由节点组成,其中包括主节点和从节点。集群按照槽进行分片,共支持16384个槽,每个主节点负责一部分的槽存储。当进行某个键的存取操作时,首先根据键计算出对应的槽值,然后根据槽值去对应的节点进行操作。从节点负责备份主节点,并且当主节点失效时,进行故障转移。
发布订阅
redis的发布订阅系统底层通过字典和链表实现。
事务
|
|
待研究
- 内存回收算法