
消息队列的历史
从前,有个思想活跃的小伙子突然有一个idea:为什么没有一种通用的软件总线呢?因此他设计了历史上的第一个消息队列,并且在金融领域崭露头角。后来,被其他各大公司看好,各大公司开始开发自己的商用消息队列。比如IBM MQ系列产品,微软消息队列(MSMQ)。这些商用消息队列另中小型公司望而却步,并且渐渐显现出另一个比较严重的问题:这些消息队列都是各自为营,之间不能兼容。后来,JMS诞生了,通过提供公共API的方式隐藏各个消息队列之间的差异性。后来有些人觉得这样设计还是不彻底,于是AMQP诞生了。
AMQP是消息队列的开放标准。RabbitMQ就是使用Erlang语言开发的遵从AMQP的消息队列。
连接与信道
RabbitMQ使用了信道技术,好处是多个线程可以复用tcp连接。那什么是信道技术呢?官方解释,一个tcp连接上的多个虚拟连接(这就是屁话,说了半天等于没说,不明白的还是不明白)。下面讲下复用tcp连接的技术。假设,客户端与服务端有一个tcp连接,客户端有两个线程都在使用这个连接。那问题来了,两个线程同时请求服务器,服务器同时返回两个结果,我怎么区分哪个结果是哪个线程的呢?解决方案如下: 每个线程都需要一个唯一的id号。发送请求时将自己的id号发给服务器,同样服务器返回结果时,也要带上客户端发的id号。如下图所示:
===========================
---------------------------
++++ 发送请求id是1 ++++
++++ 发送请求id是2 ++++
---------------------------
---------------------------
++++ 返回结果id是2 ++++
++++ 返回结果id是1 ++++
---------------------------
===========================
因为tcp连接是全双工通信,所以发送请求和接收返回结果可以同时进行。=之间代表一个tcp连接。-之间代表tcp连接里的一个通道,其中一个用于发送请求,另一个用于接收请求。+代表一个信道,标识信道的是id。
当信道设置成confirm模式时,发布的每条消息都会获得唯一的ID。
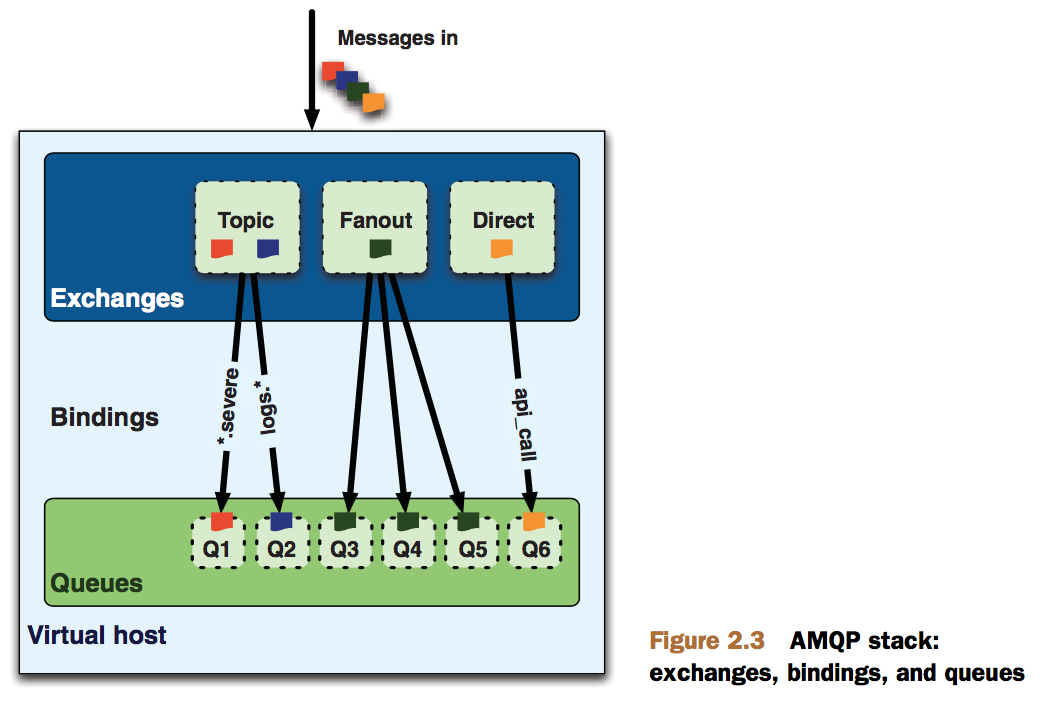
RabbitMQ的组成部分
RabbitMQ由三部分组成: 交换器、队列和绑定。三者之间的关系如下图所示:
队列
消费者从队列中取出消息,并进行处理。若有多个消费者监听同一个队列,消息则以轮询的方式发送给每个消费者,消费者需对是否收到消息进行确认,若不确认,该条消息则永不删除。若连接断开,则该条消息会重新入队,发给另一个消费者。
queue.declare # 创建一个队列
* exclusive # 队列是私有的
* auto-delete # 当最后一个消费者取消订阅后,自动删除
* passive # 探测队列是否存在
basic.consume # 持续接收消息
basic.get # 只接收一条消息
basic.ack # 确认收到消息,若auto_ack=true,则收到消息后,自动确认
basic.reject # 拒绝消息
* requeue #true,消息重新入队,发给另一个消费者。false,消息直接删除。
交换器与路由规则
交换器的类型: direct fanout topic和headers。headers允许匹配AMQP的header而非路由规则,类似direct,但性能稍差,使用场景不多。前三种如下图所示:
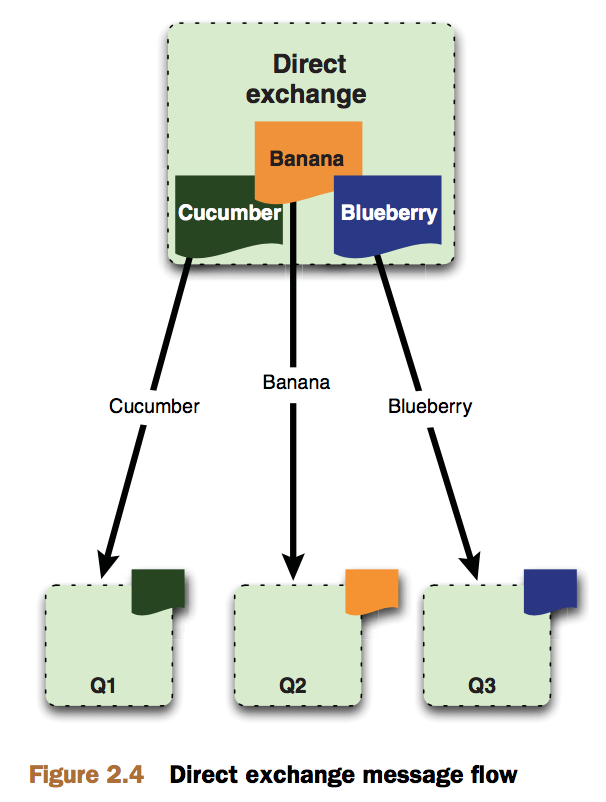
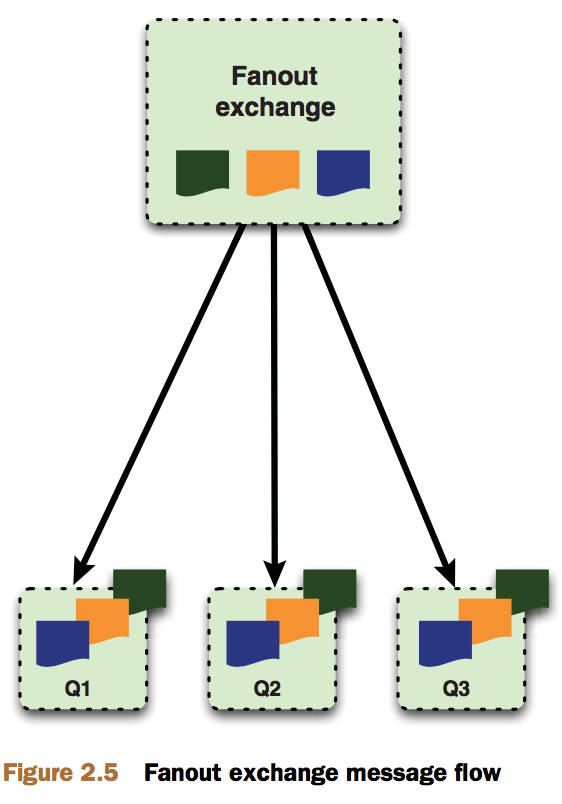
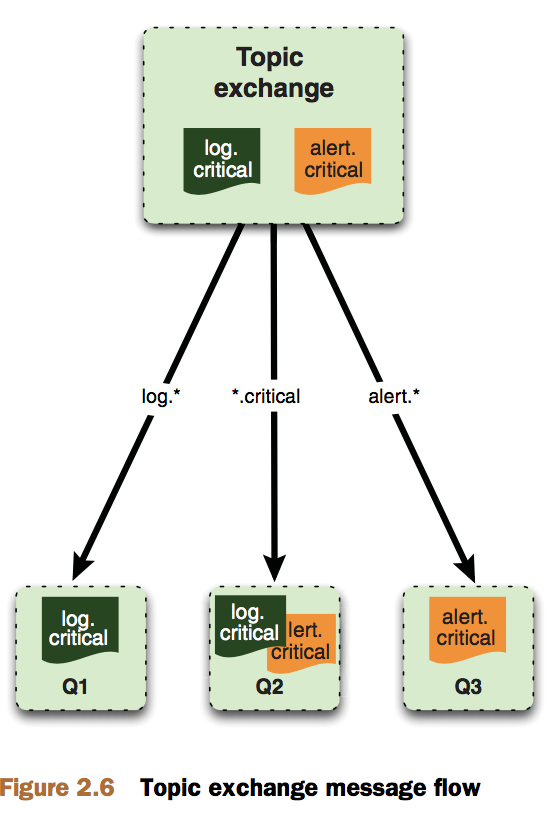
fanout交换器适用于需对同一个消息做不同处理的场景。
路由规则
|
|
相关命令
|
|
虚拟主机
一个RabbitMQ服务上可以创建多个虚拟主机,每个虚拟主机之间绝对隔离。
相关命令
|
|
消息持久化
默认情况下,RabbitMQ宕机或重启后,交换器和消息队列需重新建立,队列里面的消息也随即消失。想让消息持久化存储,必须做到以下三点:
- 把消息的投递模式选项设置为2(持久)
- 发送到持久化的交换器
- 到达持久化的队列
持久化机制:消息到达持久化交换器时,只有将消息写入到磁盘的持久化日志文件以后才会返回结果。若消息路由到非持久化队列,则该消息将会从持久化日志文件中删除;若消息路由到持久化队列,当消费者消费了该条消息后,会从持久化日志文件中将该条消息标记为等待垃圾收集。当服务器重启后,服务器会自动重建队列、交换器以及绑定关系,重播持久化日志文件到相应的队列或交换器上(取决于服务器宕机时,消息处在路由的哪个环节)。
使用消息持久化会降低服务器性能,若对性能要求很高(100000qps),可以使用一些其他机制来保证消息可靠到达。
事务
由于RabbitMQ目的是异步处理,而事务需要同步处理,所以RabbitMQ采用publisher confirms模式实现了类似的事务机制。原理参看连接与信道