
B树的背景
B树主要是为了提高硬盘的访问速度。首先,我们看下硬盘的结构:
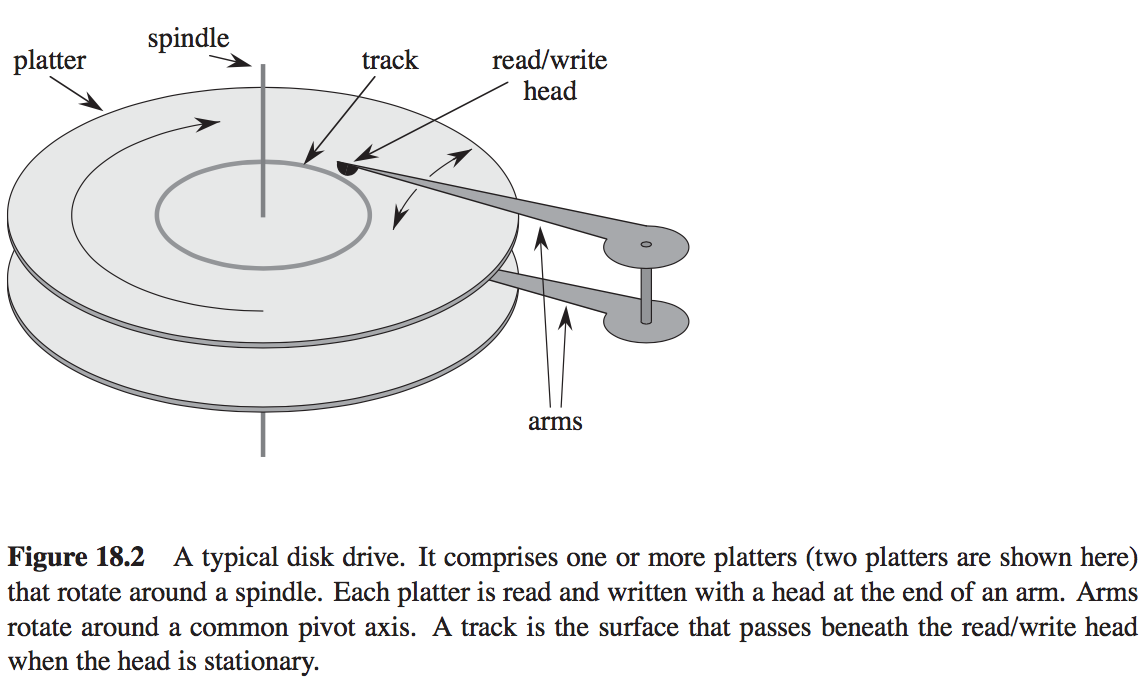
硬盘主要由中心轴(spindle),盘片(platter)、读写臂(arms)和读写头(read/write head)组成。读写臂可以在盘片上移动,当读写臂固定盘片转动时,读写头下面的部分称为磁道(track)。多个盘片只能增加磁盘的容量。
磁盘的访问是一种机械运动,主要包括盘片的旋转和读写臂的移动。磁盘的旋转速度一般在5400~15000RPM。盘片转动一圈需要的时间在8~11毫秒之间。然而,内存的访问速度是50纳秒。换言之,在我们等待某个数据转到读写头下的时间内,我们已经可以访问内存100000次了。
为了最小化机械运动的等待时间,一次硬盘访问不止读取一条数据,而是很多条。信息被分割为等大小的数据块,每块数据被称为一页。每页的数据在磁道内是连续的。每次硬盘读写一个或多个页。典型的配置是一页的数据包含$2^{11}$到$2^{14}$个字节。
由于访问硬盘数据的时间基本花费在读取磁盘的过程中,因此我们在关注程序执行时间的时候,主要关注两个指标:磁盘的访问次数和CPU的执行时间。硬盘的访问次数与每次访问磁盘时访问的页数量相关。
在典型的B树应用里,数据量太大以至于不能一次全部存储在内存里。B树算法从硬盘向内存拷贝需要的数据,拷贝内存中改变的数据到硬盘。在任何时间,B树只保存一定数量的页在内存中。因此,内存的大小不会限制B树能处理的数据的大小。
|
|
以上是对内存中对象的典型访问方式。
B树算法的运行时间主要依赖于硬盘的读写次数。因此,我们希望每次硬盘读写尽量操作更多的数据,这样可以减少硬盘的读写次数。因此,一棵B树节点的大小通常是一个完整的硬盘页的大小。一个B树节点通常包含很多关键字,B树节点的大小和关键字的大小共同限制了B树节点能拥有的子节点的数量(即分裂因子)。分裂因子越大,树的高度越低,硬盘的访问数量越少。分裂因子一般在50~2000之间。

如上图所示,一个分裂因子为1001高度为2的B树能存储十亿个关键字。由于树的根节点一直保存在内存中,因此在这课树中访问任何一个节点至多需要两次硬盘访问。
B树的定义
通常情况下,节点由关键字及与该关键字相关的其他信息页的指针组成。
B树的变种
B+树
B+树存储所有的相关信息在叶子节点,非叶子节点只存储关键字,这样使非叶子节点的分裂因子最大,降低树的高度,提高了访问速度。
B树的应用
B树被广泛应用在数据库的索引中,比如Mysql、MongoDB。
后续会对这些具体的应用进行分析,敬请期待!